SPY ETF Close Price Regression
1. Feature Preprocessing (fitted on training data only)
The preprocessing pipeline is modular and configurable via pp_steps. Each step can either overwrite ('o') or append ('a') features:
| Step | Class | Description |
|---|---|---|
cov_select | CovSelector | Select top-k features based on Spearman/Pearson correlation with target |
zscore | ZScoreScaler | Z-Score normalization (mean=0, std=1) |
winsor | Winsorizer | Clip outliers to specified quantiles (default: 1st and 99th percentile) |
pca | PCACompressor | Reduce dimensionality via PCA |
Default pipeline: cov_select → zscore → winsor → pca
Key design for avoiding data leakage:
- All preprocessing steps are fitted only on training data
- The same fitted transformers are applied to test data without refitting
- Each step fits on the data before any transformation from the current step
2. TimeSeries Conversion
- Convert preprocessed features and targets to Darts
TimeSeriesobjects - Use integer index (instead of datetime frequency) to handle trading days with irregular gaps
3. Model Training
- Train a Temporal Fusion Transformer (TFT) model from the Darts library
- Key hyperparameters:
input_chunk_length: Number of historical time steps as input (default: 30)output_chunk_length: Forecast horizon (default: 1)hidden_size,lstm_layers,num_attention_heads: Model architecture- Optimizer: AdamW with gradient clipping
- Model weights are saved to
results/<exp_name>/tft_model.pt
4. Evaluation
- Use
historical_forecaststo generate rolling 1-step-ahead predictions on both train and test sets - Convert predicted log returns back to price space using
from_logret() - Calculate MSE/RMSE in price space
- Save results:
metrics.json: Train/Test MSE and RMSEpredictions.csv: Date, ground truth, prediction, and split labelpredictions_plot.png: Visualization of predictions vs ground truth
5. Avoiding Future Data Leakage
- Preprocessing: All scalers/selectors are fitted only on training data
- Target transformation: Log returns are computed on the full dataset before splitting, ensuring proper continuity
- Evaluation:
historical_forecastswithretrain=Falseensures no future information is used during prediction - NaN handling: Only forward-fill (
ffill) is used; backward-fill is avoided to prevent leaking future data
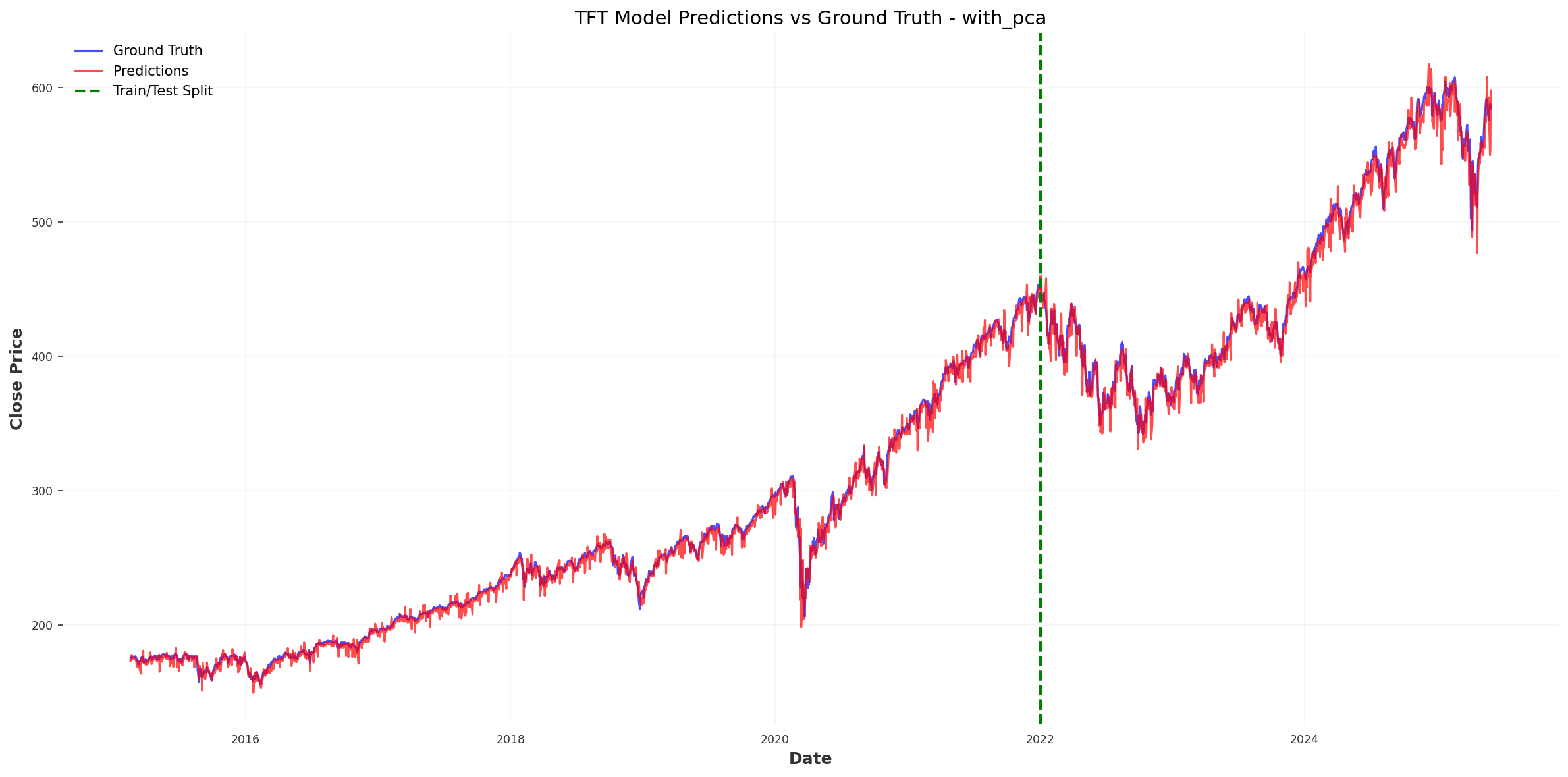
Pretrained Model Performance
The baseline model is trained with the default configuration and achieves the following performance on the test set:
- Training MSE: 29.103605906890895
- Test MSE: 89.18892824798843
The plot below visualizes the model’s predictions against the ground truth prices on the test set: